Feather format update: Whence and Whither?
Earlier this year, development for the Feather file format moved to the Apache Arrow codebase. I will explain how this has already affected Feather and what to expect from the project going forward.
Moving the Feather format to the Arrow codebase
Earlier this year, I ported the Feather file implementation to fit in with the rest of the more general Arrow C++ in-memory data structures and memory model. Reading a Feather file column is a zero-copy operation that returns an arrow::Column C++ object. These C++ containers can then be converted to pandas.DataFrame, R data.frame, or whichever desired consumer of the data.
Moving Feather development to the Arrow codebase has made the implementation substantially simpler, and Feather users immediately benefit from any performance improvements or general Arrow-related development work. So Feather has gotten faster and faster in Python this year as we’ve worked on enhancing the bridge between pandas and Arrow this year.
One problem with moving Feather to the Arrow codebase is that there are not yet R bindings available for the Arrow C++ libraries. As soon as we have R bindings available for Arrow, I will be quite keen to get to work adding new Feather features and transitioning Feather internally to reuse Arrow’s stream format and metadata, making the implementation even simpler.
Performance improvements in Feather for Python users
I released Feather 0.4.0 on May 24 as a simple wrapper around pyarrow.feather. So this means that when pyarrow gets faster, so does feather. One of the primary benefits has been multithreaded conversions. We have had multithreaded conversions from Arrow to pandas since Arrow 0.2.0. I recently implemented multithreaded conversions from pandas to Arrow, and these will ship in Arrow 0.8.0.
Let’s take a look at read speeds in Feather 0.3.1 (which had a self-contained implementation) compared with Feather 0.4.0 using Arrow 0.7.1. To do this, I generated a 512 MB DataFrame with floating point columns, write it to Feather, then measure the performance for reading it completely back into memory. I varied the number of columns in the DataFrame while keeping the total data size the same. For some reason, Feather 0.3.1 is faster reading this dataset with 50 columns than with 10 columns. You can look at the complete notebook for the benchmark.
Perhaps amazingly, Feather 0.4.0 based on pyarrow 0.7.1 is much faster than Feather 0.3.1:
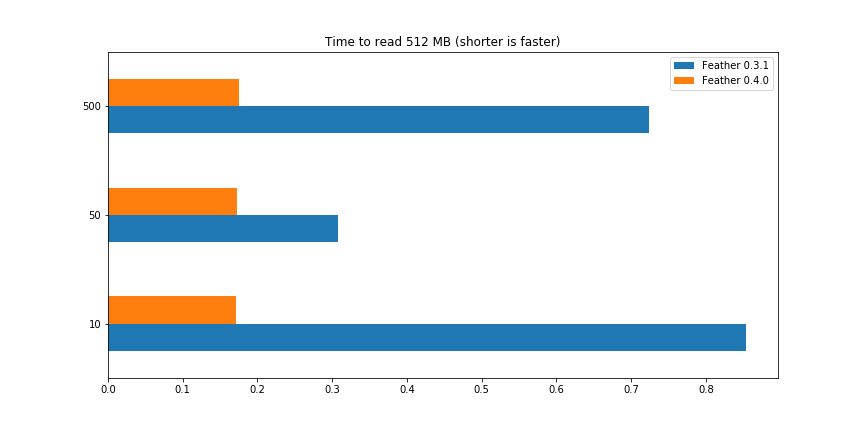
To put this performance concretely: on my laptop, Feather 0.3.1 can read a 50-column DataFrame at about 1.6 GB/s while Feather 0.4.0 (based on pyarrow 0.7.1) can read at about 2.9 GB/s, a reduction in runtime of over 40%.
This improved performance is for multiple reasons:
- Multithreaded conversion from Arrow’s bitmap-based null encoding to pandas’s
NaN-based null encoding for doubles - More precise and efficient creation of the pandas DataFrame internal data structure
What to expect in the future
Until R bindings for Apache Arrow ship, it will be difficult to innovate on Feather’s feature set, since the existing R feather library in CRAN is based on the Feather 0.3.1 codebase from the wesm/feather repository. Once that happens, we should be able to make R’s Feather read performance faster and more consistent as we have with the Python implementation above.
I’m excited to engage with the R community on this work and look forward to delivering more Apache Arrow-based IO and computation tools to both the R and Python communities.