
Ursa Labs January 2019 Report
ursa labs
work
Ursa Labs had a busy January that went by too quickly. After a high-intensity 3 months of development, we helped release Apache Arrow 0.12 on January 20th. A good chunk of our time was spent fighting fires (in packaging and builds) related to the continued…
Announcing Ursa Labs’s partnership with NVIDIA
ursa labs
work
I’m excited to announce that NVIDIA AI Labs has signed on as a supporter of Ursa Labs. NVIDIA’s new open source RAPIDS data science platform uses Apache Arrow for an interoperable representation of tabular data (data frames). We are looking forward to collaborating on our respective development roadmaps and growing the ecosystem…
Streaming Columnar Data with Apache Arrow
apache arrow
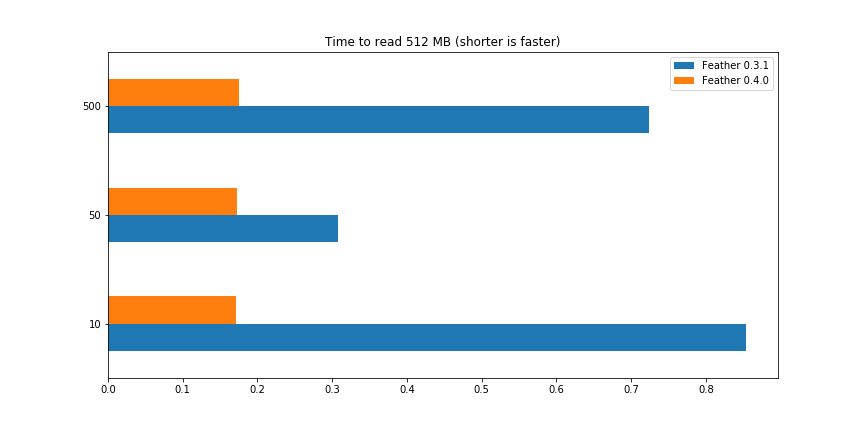
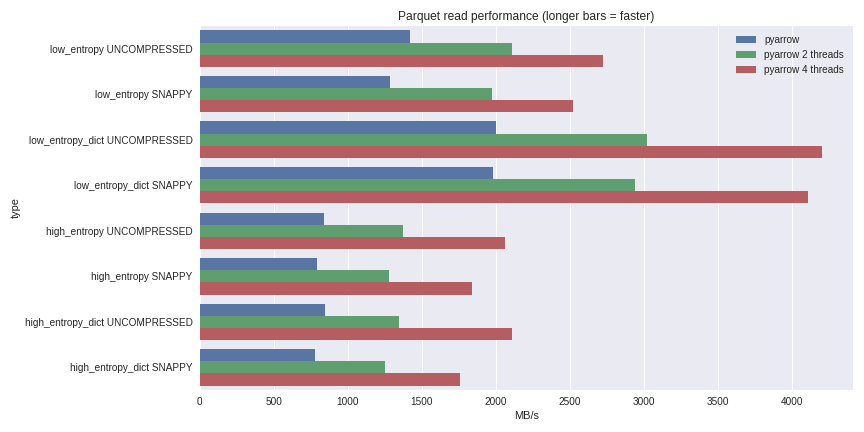
Over the past couple weeks, Nong Li and I added a streaming binary format to Apache Arrow, accompanying the existing random access / IPC file format. We have implementations in Java and C++, plus Python bindings. In this post, I explain how the…
The problem with the data science language wars
rants
data science
python
r
I really enjoyed the cheeky blog post by my pal Rob Story.
Thoughts on joining Cloudera
work
After some unanticipated media leaks (here and here), I was very excited to finally share that my team and I are joining Cloudera. You can find out all the concrete details in those articles, but I wanted to give a bit more intimate perspective on the move and what…

No matching items